



Executive summary
In the absence of market underwriting and claims data on AI exposures, the Lloyd’s Market Association (LMA) conducted a market opinion survey to explore key issues relating to insured AI risks.[1] The survey explored:
- whether insureds are using AI, right now, in ways that could cause or contribute to claims
- which loss scenarios LMA members are most concerned about
- views on whether or not insureds are managing the risks adequately
- views on the potential scale of losses.
The survey was conducted in mid-2025, with responses invited on a wide range of potential AI loss scenarios (see Annex A for the full list). Four scenarios have been included in this analysis:
- Professional Indemnity: “AI produces erroneous advice/service to clients, causing a loss.”
- Product Recall: “Recall required following property damage and/or bodily injury caused by defective products designed and/or manufactured by AI, e.g. food contamination.”
- Accident and Health (A&H): “Self-driving car error causes injury to passenger: first-party A&H policy could respond in first instance.”
- Cyber: “System downtime caused by AI malfunction and resulting Business Interruption.”
Results
Based on the opinions provided by LMA members to the survey (of which 94% were underwriters), each scenario has been rated for viability (score out of 5), magnitude (score out of 5) and overall impact (score out of 25; see methodology for further information).
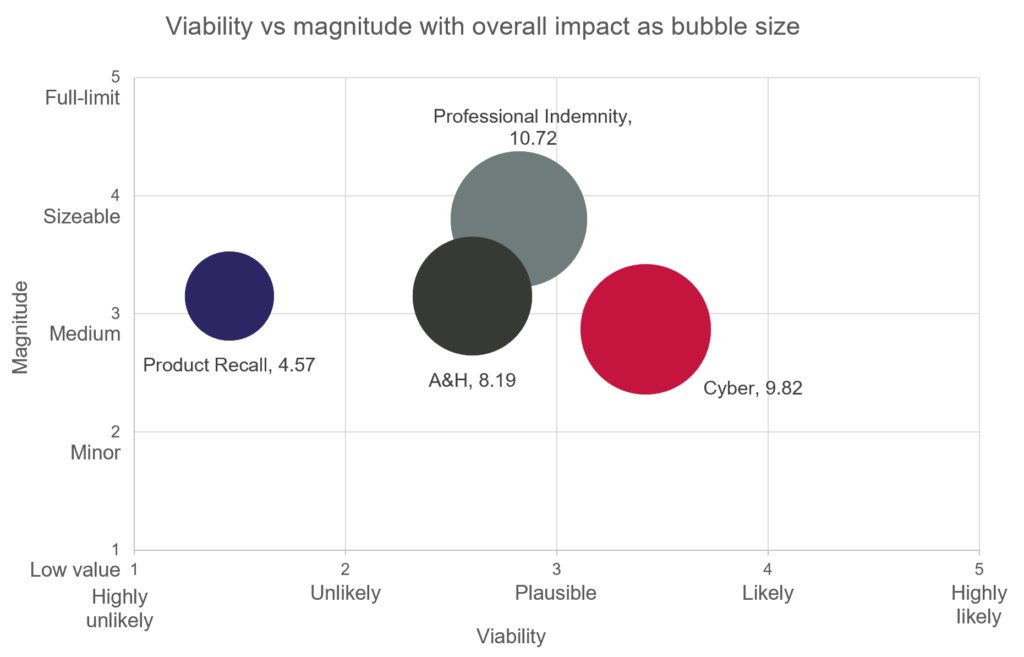
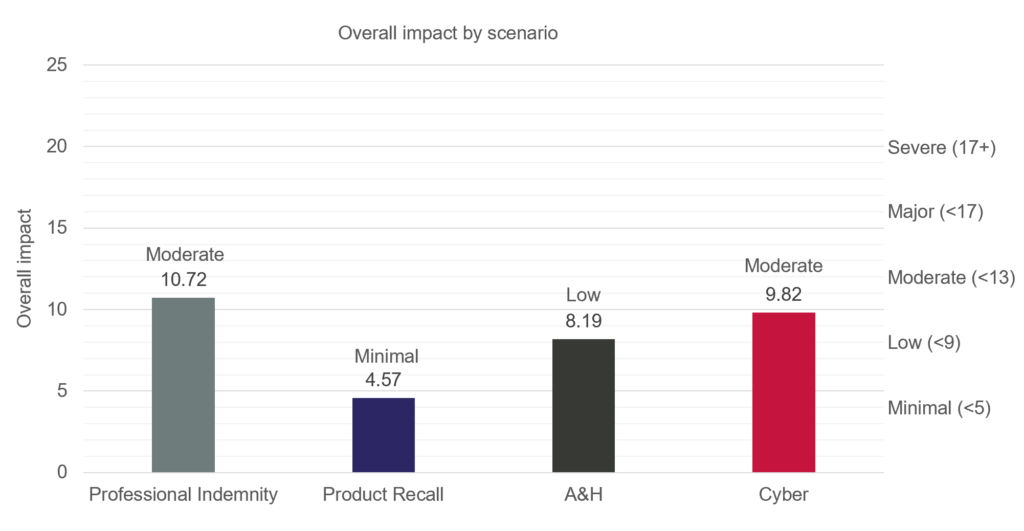
| Viability | Magnitude | Overall impact | |
| Professional Indemnity | 2.82: Plausible | 3.8: Medium | 10.72: Moderate |
| Product Recall | 1.45: Highly unlikely | 3.15: Medium | 4.57: Minimal |
| A&H | 2.6: Plausible | 3.15: Medium | 8.19: Low |
| Cyber | 3.42: Plausible | 2.87: Minor | 9.82: Moderate |
Answers to research questions
Are insureds using AI, right now, in ways that could cause or contribute to claims?
Yes.
Three of the four scenarios (Professional Indemnity, A&H and Cyber) were rated as “plausible” (the middle rating on the five-point scale), indicating that respondents felt that these loss scenarios could occur in real-world settings but were credible risks rather than “likely” or “very likely”.
The Product Recall scenario was rated as “highly unlikely” for viability, perhaps indicating that insurers do not believe that insureds are generally using AI, at present, for product design or manufacturing, in ways that could lead to insured losses caused by AI errors.
The survey also indicated that AI usage (in the ways described in the scenarios) was expected to increase, which could increase exposure to AI error-driven losses in the future. 67% of the total responses agreed that AI usage would increase in the next 12 months and 86% agreed that AI usage would increase in the next two to three years.[2]
Respondents to the Professional Indemnity scenario indicated more regularised use of AI in financial and professional lines at present, compared with other product areas, with 100% of responses suggesting AI was being used, at least to some extent, right now by insureds. 79% of responses also suggested AI usage is expected to increase over the next 12 months.
In Product Recall, live exposure to risks arising from use of AI in product design or manufacturing is currently viewed by respondents as low. However, significant growth potential is expected in the short to medium term.
Respondents to the Cyber scenario agreed that there was at least some degree of system failure risk posed by AI usage at present.

Note: This survey did not assess any protective effects of AI use – the focus was on loss potential only.
Which loss scenarios are LMA members most concerned about?
Of the four scenarios in this summary, the Cyber scenario received the highest score for viability, while the Professional Indemnity scenario received the highest scores for both magnitude and overall impact. The overall impact ratings (calculated by multiplying the viability ratings by magnitude ratings) scored the Professional Indemnity and Cyber scenarios as “moderate” (the middle rating, in between “low” and “major”).
Respondents generally agreed that there is considerable potential for AI-related losses to arise in the provision of professional services, given the wide usage of AI large language models by insureds.
The potential overall impact of the product recall scenario was rated as “minimal” and the A&H scenario was rated as “low”.
Note: The level of concern/scale of any loss would also depend on the terms and conditions of applicable wordings and use of exclusions. In these scenarios we did not ask respondents to apply a specific wording, given a wide range of cyber clauses are in use in most lines of business. When estimating loss potential, we asked respondents to assume that the loss was covered. Also see Section 5: Treatment of AI risk in LMA model wordings.
Are insureds managing the risks (of AI errors causing insured losses) adequately?
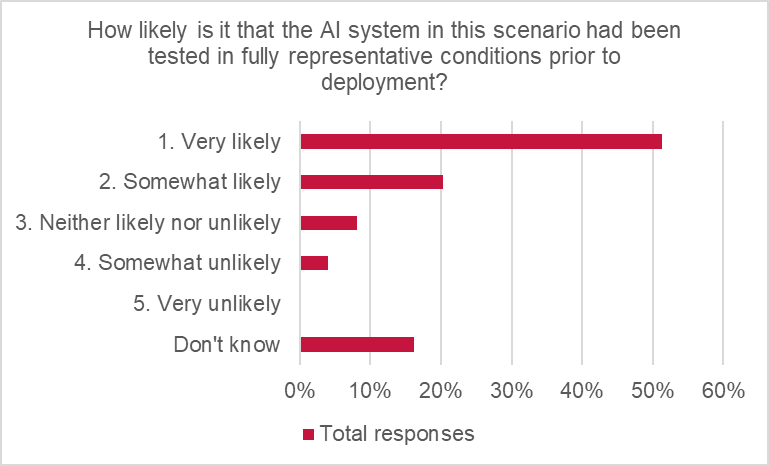
LMA members believe that they largely are, with some variability. The total responses indicated reasonable confidence that insureds were testing AI use in representative conditions, with more than two-thirds of responses suggesting it was “very likely” (51%) or “somewhat likely” (20%).
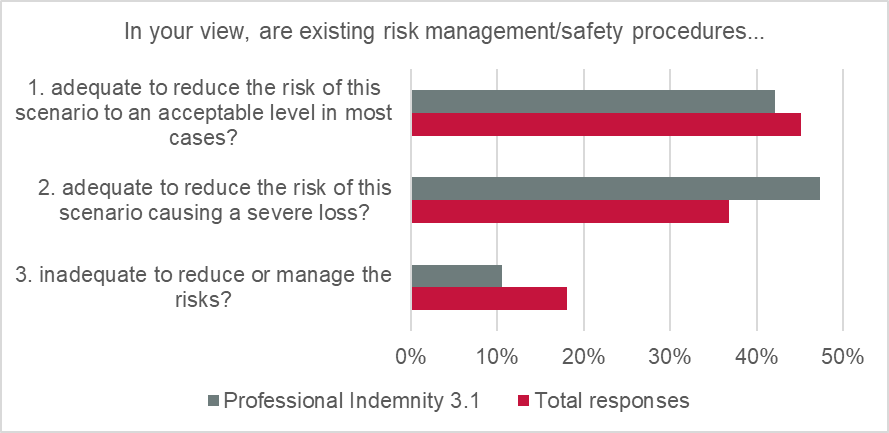
Only 18% of global responses suggested that insureds’ existing AI risk management/safety procedures are inadequate. The majority of responses indicated that risk management is either “adequate to reduce the risk to an acceptable level in most cases” (45%) or “adequate to reduce the risk of this scenario causing a severe loss” (37%).
In the Professional Indemnity scenario, 89% of respondents felt that existing risk management/safety procedures were “adequate” (vs 11% “inadequate”). This indicates a high degree of confidence in insureds to manage the risks arising from use of AI systems.
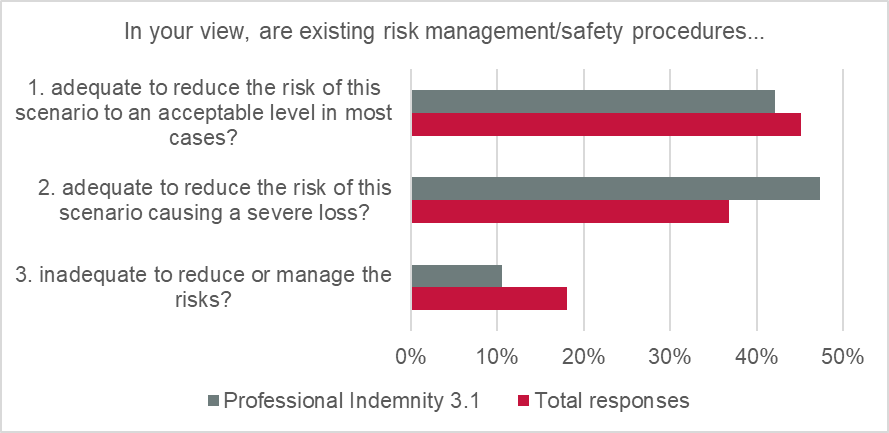
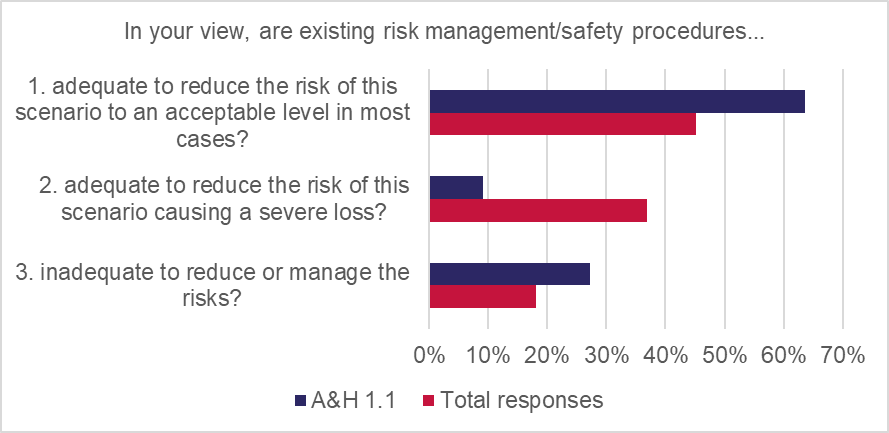
In the A&H scenario, where losses arise due to an accident caused by a self-driving vehicle (and given the obvious risks arising from AI failure in this scenario), it is reasonable to expect extremely careful risk-management strategies to be deployed. The majority of respondents support this hypothesis, with 64% of responses agreeing that testing by risk managers was adequate to reduce the risk to an acceptable level “in most cases” and 9% said testing was “adequate to reduce risk of causing a severe loss”. However, 27% said that testing was “inadequate to reduce or manage risks”, so this confidence was not universally shared.
Note: The survey explored the confidence levels/opinions of respondents regarding insureds’ risk management. The survey did not collect risk management data, claims information or data from external sources.
Respondents’ views on the potential scale of losses?
The magnitude ratings for all scenarios were either “medium” or “minor”, with respondents clearly not fearing full-limits exposure, based on weighted-averages (note: although there were a wide range of views on the loss potential of each scenario – see detailed analysis below).
The Professional Indemnity scenario produced the highest magnitude rating of 3.8 out of 5, at the higher end of the “medium” rating. The potential for losses was estimated as reasonably significant, with 58% of responses of the view that losses arising from this type of scenario might reach full policy limits (vs 33% of the total responses) and 5% of responses estimated that losses might be around 80% of policy limits.
Despite attracting the highest score for viability, the Cyber scenario’s magnitude rating was “minor” (2.87 out of 5), indicating the view from respondents that this scenario is likely to produce relatively low-level losses, with over a third of respondents suggesting a loss might scale at 15% of typical policy limits. However, one quarter indicated losses arising from this type of scenario might reach full policy limits.
Note: These observations are indicative of the views of the survey respondents and have been extrapolated to make general observations in some cases; the actual values of any individual loss would depend on the circumstances, policy wording, applicable terms and conditions, limit of coverage, etc.
Treatment of AI risk in LMA model wordings
Drawn from a related piece of work commissioned by the LMA Chief Underwriting Officers’ Committee, Section 5 of this paper sets out a high-level analysis of potential AI exposures arising in LMA model Cyber wordings. A summary table of the current position is set out in Annex 2.
Conclusions
- The risks presented by the AI loss scenarios reviewed in the survey attracted, on the whole, only a modest degree of concern amongst underwriters. The risks were widely expected to grow in the future.
- Respondents felt that the Professional Indemnity scenario was the most concerning of the scenarios reported on and Product Recall was the least concerning.
- Testing and risk management by insureds is key to ensuring that the risks are managed to an acceptable level.
- The survey attracted a wide range of views and there is a lack of underwriting and claims data about AI exposures. Case studies, with detailed event profiles, applying specified wordings and limits of cover may usefully reveal more information about potential AI exposures.
Disclaimer
This document has been produced by the Lloyd’s Market Association (LMA) for general information purposes only. While care has been taken in gathering the data and preparing the document, LMA makes no representations or warranties as to its accuracy or completeness and accepts no responsibility or liability for any loss arising as a result of any reliance placed on the contents. This document does not constitute legal advice.
[1] The LMA definition of AI, for the purposes of this survey, is: “software that is automated and generates information outputs based on a statistical model of data taken from similar or informative scenarios”. See introduction below for further information.
[2] “Total responses” refers to all responses across the entire range of scenarios
Introduction
Artificial intelligence (AI) systems and tools have been an extremely hot topic in insurance for several years and are likely to remain so for the foreseeable future. Many boards of Lloyd’s managing agents have recently cited AI risk as second only to geopolitical risks on risk registers.[1] In order to explore some of the key themes emerging from insured AI risk, the LMA conducted a survey of members, asking for views across a range of potential loss scenarios.
Primarily, the survey was intended to research:
- LMA members’ views on whether insureds were using AI, right now, in ways that could cause or contribute to claims
- which loss scenarios LMA members were most concerned about
- LMA members’ views on whether insureds were managing the risks adequately
- members’ views on the potential scale of losses.
Definition of AI
The definition of AI used in the survey describes an AI system as “software that is automated and generates information outputs based on a statistical model of data taken from similar or informative scenarios.”
In the survey, respondents were encouraged to think about AI very broadly, including any computer system able to perform tasks that normally require human intelligence, under varying and unpredictable circumstances, without significant human oversight, such as visual perception, speech recognition, decision making and language translation. AI systems could include large language models, machine learning software and deep learning software.
Use of cyber affirmations and exclusions in policy wordings
The survey also collected some general views on whether AI exposures might typically be covered or excluded in policy wordings. The LMA previously explored this issue and briefed the LMA Chief Underwriting Officers’ Committee in 2024 on a high-level analysis of LMA model wordings exposure to a list of AI loss scenarios. An updated summary table of this work is provided in Annex 2.
Some high-level questions on the use of exclusions were included in the survey but are not reported in this summary. On review, it was not appropriate to report on generalised observations about coverage/exclusion of losses without narrowing down the scenario(s) to an exact set of circumstances and the exact clause that was used; this is outside the scope of the survey and would be more accurately researched via case studies.
Disclaimers
The observations reported in this summary do not relate to specific losses, wordings or exclusions. An authoritative view on coverage or exclusion of losses arising from a specific loss would require a review of the facts and circumstances and application of the policy wording(s) used.
Also, we did not explore the protective effects of AI in this survey, taking into account the benefits that could accrue to insureds and (re)insurers arising from the use of AI, which could be material.
[1] Lloyd’s, 2025. Emerging Risks Report.
Methodology
A 31-question survey was developed and issued by the LMA to members in April 2025. Members were invited to select any of the listed scenarios and complete the question set and were encouraged to submit responses for any of the scenarios within their area(s) of expertise.
The LMA developed a lengthy suite of AI loss scenarios: 65 in total, across 10 high-level classes of business. Some scenarios were invented for this exercise and some were based on events that have (or may have) already occurred. The scenarios were validated with the LMA’s underwriting committees, to ensure that each scenario was believed to be technically viable, even where the probability of a particular scenario occurring was suspected to be very low.
The scenarios were deliberately broadly drafted, to try to encompass a wide range of AI use cases/loss scenarios and attract as many responses as possible, on the basis that this survey is exploring AI risks at a high-level only. For example, in the Professional Indemnity Scenario 3.1 “AI produces erroneous advice/service to clients, causing a loss”, the type of advice/service provided is not specified as the intention was to capture any type of advice or service provided to any type of professional client. This approach does have its limitations in terms of the degree to which the views and opinions captured might be generally applicable, but the intention was to capture high-level views on generic AI loss scenarios for major insurance products.
Respondents
144 responses to the survey were collected in Q2 and Q3 2025, 94% of which were from underwriters. The distribution of responses by job role was:
- Leadership/C-suite: 12%
- Head of Class/Senior Underwriter/Senior Manager/Senior Product Manager: 33%
- Manager: 31%
- Team member: 25%
Many respondents advised that the survey questions were difficult to answer. Not enough responses were collected to analyse every scenario included in the survey. Therefore, this summary focuses on the four scenarios with the highest response rate, with a minimum threshold of six responses per scenario, though up to 19 responses were received for some scenarios.
Respondents reported the survey as difficult to complete, for two main reasons:
- Insurers are remote to insureds’ use of AI; it is not always clear whether an insured is using AI in the ordinary course of their business and little data on AI usage is currently collected during underwriting, so survey questions exploring this usage have relied on underwriters’ views and opinions rather than data.
- There is a lack of claims data on AI contribution to losses, again meaning that the survey responses are informed by views and opinions rather than data in most cases.
Future research may be able to draw more directly on underwriting and claims data. However, the key observations arising from this survey still address the LMA’s overall goal of contributing to the sum of knowledge on AI risks and sharing the insights arising from this research with LMA members.
Scenario viability, magnitude and overall impact ratings
Each of the four scenarios that feature in this analysis have been given a viability rating and a magnitude rating, to summarise respondents’ views on these core issues. The ratings are based on an assessment of respondents’ views on key questions in the survey, regarding whether the scenarios are believed to be technically possible or not, and the level of concern about the loss potential. An overall impact rating for each scenario has also been produced by multiplying the viability and magnitude ratings together.
The viability rating is an assessment of whether the scenario is believed to be technically possible or not, based on responses to questions that probed:
- whether AI was thought to be in use in live situations, in the way set out in the scenario
- if so, whether it was widely or narrowly deployed
- whether AI was making “real-world” decisions.
The viability rating is expressed on a five-point Likert scale, using weighted average responses:
| Viability rating | Rationale | |
| 1 | Highly unlikely | Responses indicated that this scenario was highly unlikely to occur |
| 2 | Unlikely | Responses indicated that this scenario was unlikely to occur |
| 3 | Plausible | Responses indicated that this scenario was plausible |
| 4 | Likely | Responses indicated that this scenario was likely to occur |
| 5 | Highly likely | Responses indicated that this scenario was highly likely to occur |
The viability rating also touches on potential frequency; the higher the score, the more likely respondents felt the scenario was to occur and produce a real loss event.
The magnitude rating summarises respondents’ opinions on the potential scale of loss, should the scenario occur for real. The rating is drawn from opinions received on the question exploring the potential scale of loss, expressed as a percentage of typical limits of cover. The magnitude rating is expressed on a five-point Likert scale, using weighted average responses:
| Magnitude rating | Rationale | |
| 1 | Low value | Responses indicated that this scenario could produce low-value losses only |
| 2 | Minor | Responses indicated that this scenario could produce minor losses |
| 3 | Medium | Responses indicated that this scenario could produce medium losses |
| 4 | Sizeable | Responses indicated that this scenario could produce sizeable losses |
| 5 | Full limit | Responses indicated that this scenario could produce full-limit losses |
An overall impact rating for the four loss scenarios has been produced by multiplying the viability rating and magnitude rating of each scenario together. This rating is intended to summarise the respondents’ opinions on the potential overall impact of a loss scenario, reflecting views on both the viability of the scenario and potential scale of loss in the event the scenario occurred.
| Overall impact rating | Rationale | |
| <5 | Minimal | Overall impact (per loss) estimated as potentially minimal |
| <9 | Low | Overall impact (per loss) estimated as potentially low |
| <13 | Moderate | Overall impact (per loss) estimated as potentially moderate |
| <17 | Major | Overall impact (per loss) estimated as potentially major |
| 17+ | Severe | Overall impact (per loss) estimated as potentially severe |
Note: The ratings are intended to be indicative of the opinions of respondents to the survey; they are not based on actuarial calculations or driven by claims, exposure or risk management data.
Key loss scenarios
Detailed analysis and commentary is provided below on four scenarios:
- Professional Indemnity scenario 3.1: “AI produces erroneous advice/service to clients, causing a loss.”
- Product Recall scenario 4.13: “Product Recall due to property damage and/or bodily injury caused by defective products designed and/or manufactured by AI, e.g. food contamination.”
- Accident and Health (A&H) scenario 1.1: “self-driving car error causes injury to passenger: first-party A&H policy could respond in first instance.”
- Cyber scenario 10.1: “System downtime caused by AI malfunction and resulting business interruption.”
Responses to each of the four scenarios have been collated into three areas of analysis:
- The use of AI by insureds and growth potential in the near future.
- Risk management.
- Potential impact on losses.
For each of the four scenarios, a rating for viability, magnitude and overall impact has been provided. Please see Section 3 above for further information on the methodology of these calculations, as well as commentary on the trends and data points of interest.
Professional Indemnity scenario
Scenario 3.1: “AI produces erroneous advice/service to clients, causing a loss.”
Viability rating: Plausible (2.82 out of 5)
Magnitude rating: Medium (3.8 out of 5)
Overall impact rating: Moderate (10.72)
This scenario is deliberately broadly drafted and was intended to capture views on circumstances such as:
- Incorrect tax advice provided to a client by an accountancy firm, due to a mistake made by AI software in analysing financial data.
- Negligent legal advice provided to a client by a law firm, due to an AI program “hallucinating” (relying on non-existent case law).
- Architectural blueprints containing material errors, supplied by a firm of architects that relied on faulty AI research.
Use of AI by insureds and growth potential
Respondents indicated more regularised use of AI in Professional Indemnity at present, compared with other product areas (excluding the Cyber scenario reported on below):
- 47% estimated that AI is being used “in a few cases”.
- 37% estimated that AI is being used “in some cases” (vs 26% of the total responses).
- 16% of responses indicate AI is being used “in majority of cases” (vs 3% of the total responses).

Use of AI is estimated to be growing more rapidly in this area than other products/scenarios; around 80% of respondents expected wider usage of AI in next 12 months (vs 67% in the total responses).
There were mixed views on whether AI was making “real-world decisions” at present.
Risk management
56% of respondents felt that it was “very likely” that adequate testing was taking place (vs 33% answering “don’t know”).
89% felt that existing risk management was “adequate” (vs only 11% “inadequate”); this indicates a high degree of confidence in insureds to manage the risks arising from use of AI systems.
Losses
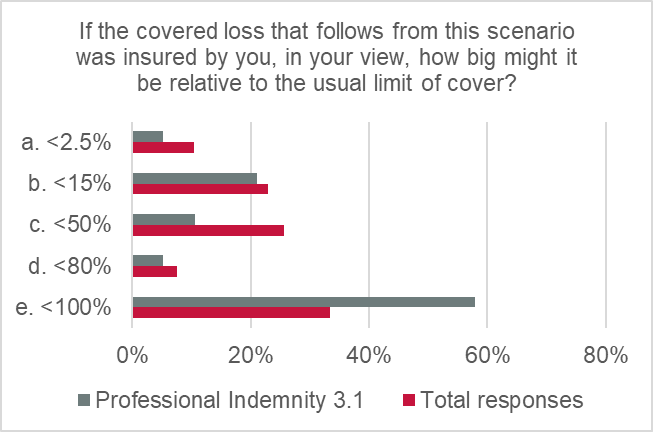
The potential scale of losses was estimated as reasonably significant:
- 58% thought that losses arising from this type of scenario might reach full policy limits (vs 33% of the total responses).
- 5% estimated losses might be <80% of policy limits (the second highest category of loss valuation).
Observations and commentary
There is clearly considerable potential for AI-related losses to arise in the provision of professional services, given the wide usage of AI (e.g. large language models) by insureds. All respondents provided a positive response on the question of AI usage in the way envisaged in the scenario, although just under half felt that AI was only being used “in a few cases”. This combined view is indicated in the viability rating of “plausible”, with a weighted score of 2.73 out of 5.
However, there is some confidence in insureds’ management of this risk. The magnitude rating (which reports views on the potential scale of loss, per event) was “medium”, although a score of 3.8 does position the potential loss at the higher end of this bracket.
The overall impact rating for this scenario was “moderate”, with a score of 10.37, which was the highest rating of the four scenarios included in this analysis. This shows that the overall level of concern is in the middle of the scale, due to a combination of wide usage and the sizeable (but not severe) estimated potential scale of loss.
The risks envisaged in this type of scenario are not necessarily being considered as a new exposure by LMA members. Reliance on AI may be analogous to reliance on (for example) junior staff producing tax calculations, legal research or technical drawings. The difference with AI might be a matter of scale. We would also note that the key function of AI is to use computing speed and power to let the system do the work and overcome human limitations; the benefits cannot be fully realised if the output must be constantly overseen by human supervisors.
Product Recall scenario
Scenario 4.13: “Recall required following property damage and/or bodily injury caused by defective products designed and/or manufactured by AI, e.g. food contamination.”
Viability rating: Highly unlikely (1.45 out of 5)
Magnitude rating: Medium (3.15 out of 5)
Overall impact rating: Minimal (4.57)
This scenario was intended to collect views on product recall exposures that might arise from AI errors in a manufacturing process, such as:
- Food production that leads to a contamination incident, due to (for example) a harmful amount of an ingredient being added to a food product.
- Children’s toys being produced with sharp edges or abrasive or corrosive surfaces.
- Construction/automotive products with defects that cause component failures under stress, leading to fire/explosion/physical damage.
The intention was to explore views on whether AI was being used in product design and manufacturing by insureds at present and the loss potential that might arise in the event of errors. Similar scenarios were posed in respect of general liability exposures in scenarios 4.6 and 4.11a (not included in this analysis).
Use of AI by insureds and growth potential
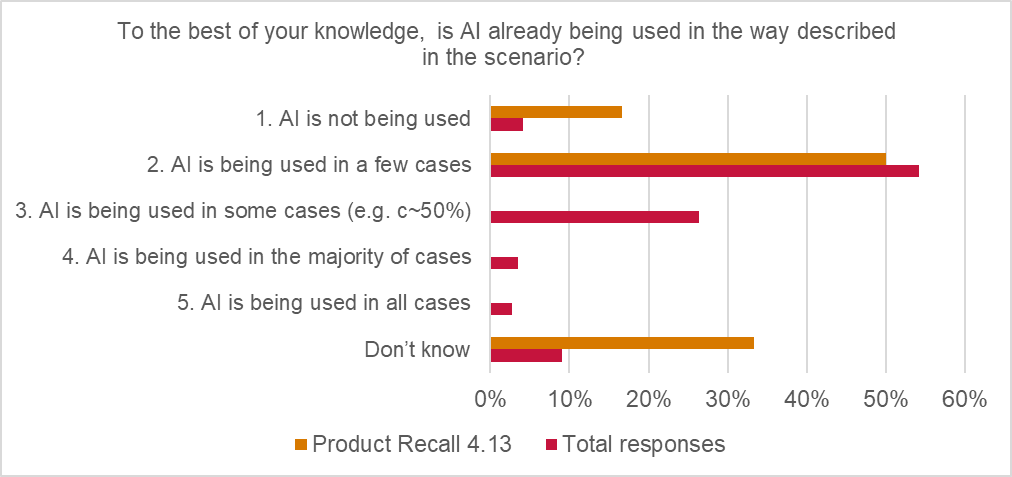
Respondents estimated that AI use is very limited in this type of scenario at present:
- 17% of respondents advised that AI was not being used in this way by insureds
- 50% of respondents selected only “in a few cases”
- 33% replied “don’t know”.
However, regarding growth potential:
50% of respondents expected strong growth in the use of AI (in product design and manufacture) in the next 12 months, and 67% in the next two-to-three years.
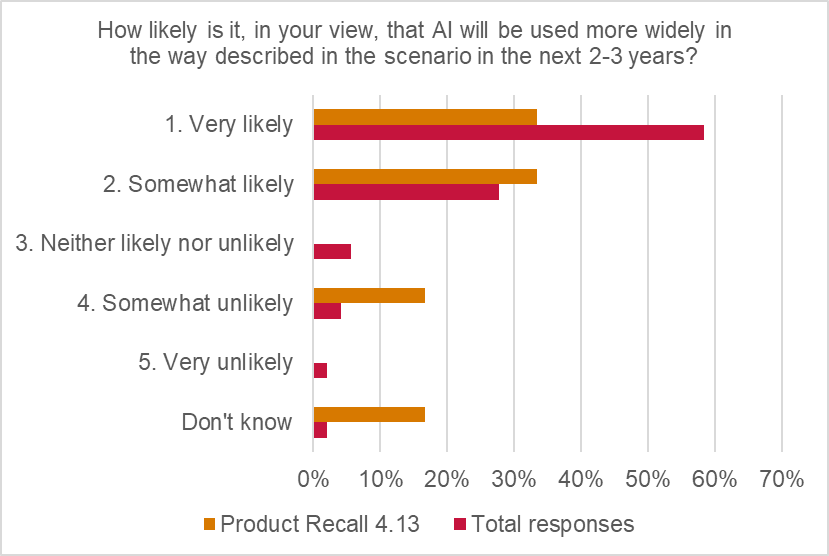
This indicates that while live exposures to risks arising from use of AI in product design/manufacturing were currently viewed as low, significant growth potential is expected, in the short to medium term.
Risk management
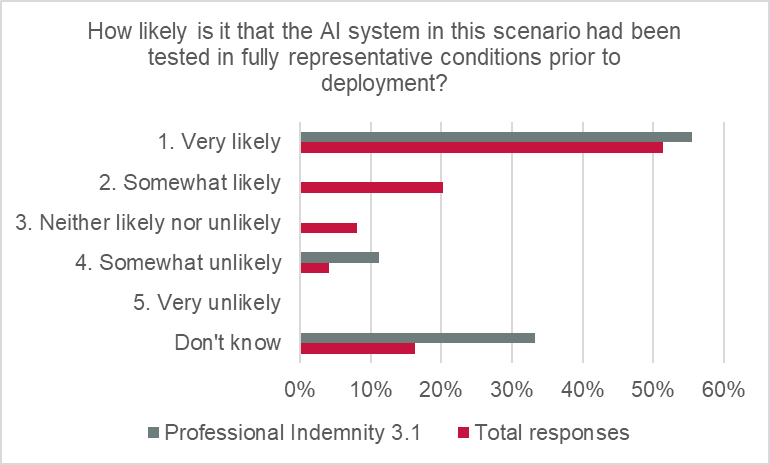
Respondents were reasonably confident that AI systems were being tested in representative conditions prior to deployment, with more than two-thirds of responses suggesting it was “very likely” (51%) or “somewhat likely” (20%). The assessment is very close to the total responses.
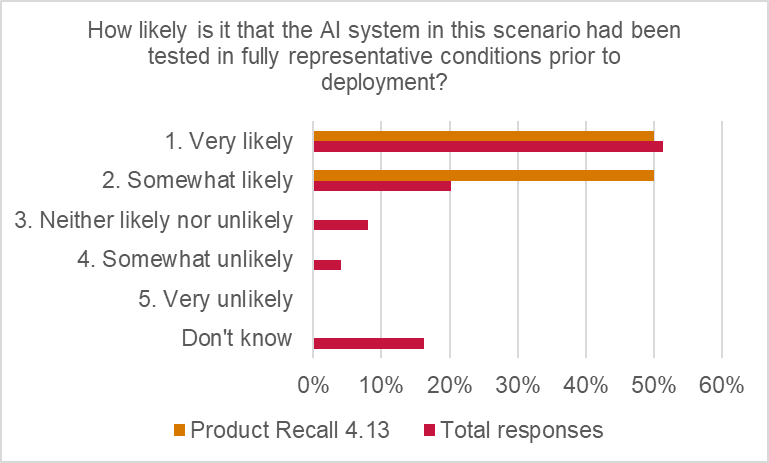
Moreover, the general view was that existing risk management by insureds was adequate. 33% of respondents indicated that risk management procedures were “adequate to reduce the risk of this scenario to an acceptable level”, while 50% indicated procedures were “adequate to reduce the risk of this scenario causing a severe loss”.
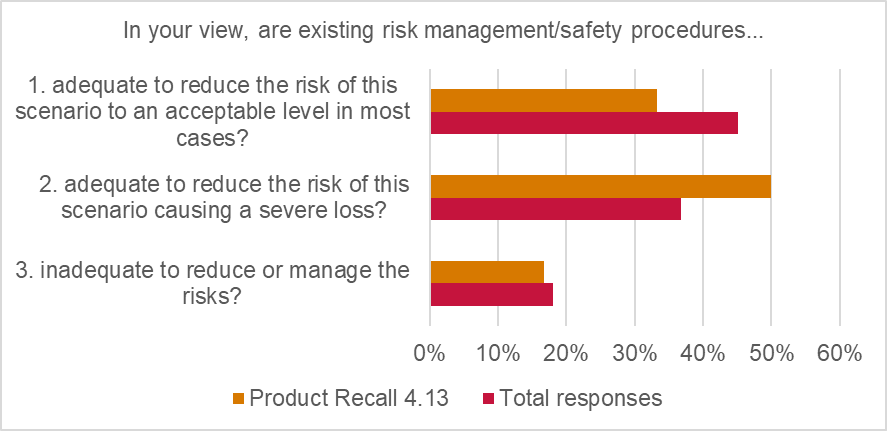
Losses
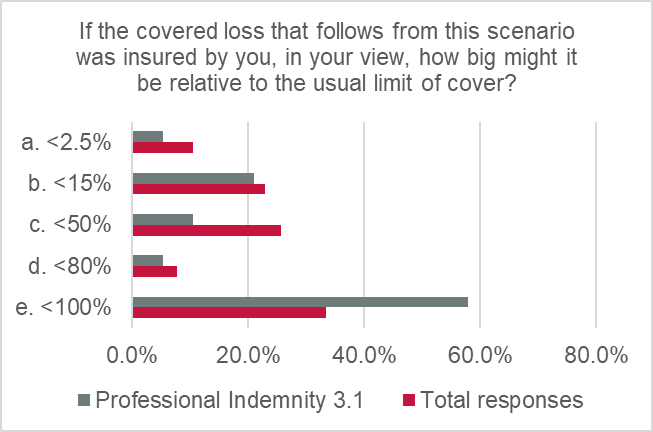
The potential for sizeable losses was estimated as fairly significant: 50% of responses indicated up to full-limit losses arising from this type of scenario and 33% of responses suggested “up to 50% of limit” losses arising from this type of scenario.
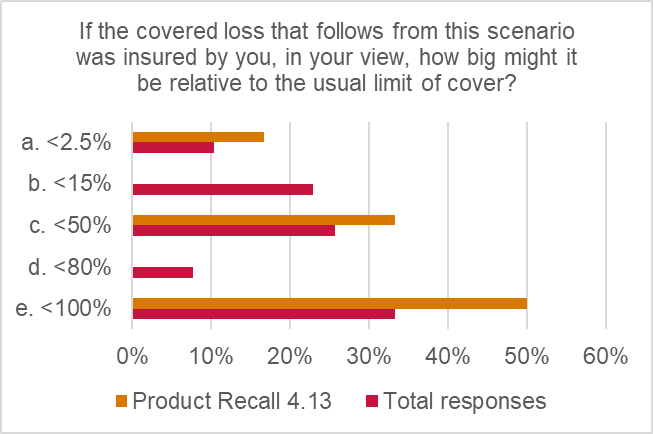
Observations and commentary
The assessment of current usage of AI in the way described in the scenario is reflected in the “highly unlikely” viability rating score (1.45 out of 5). Respondents did not think that AI is being used to make critical decisions in product design or manufacturing at present. However, it is interesting that respondents felt that the potential for large losses, per claim, was still present, hence the “moderate” magnitude rating (weighted score of 3.15 out of 5). There was clearly some concern about the potential scale of loss arising from this type of event, as indicated by a combined 83% of respondents concerned about up to 50%-100% of full-limit losses.
However, weighing the above two factors together, the overall impact rating is “low”, indicating that respondents were relatively relaxed about the overall risks presented by this scenario, dominated by views on the low degree of involvement of AI in manufacturing at present. The only cloud on the horizon is the strong anticipated growth of use of AI in product design and manufacture that is expected in the near future.
Accident and Health (A&H) scenario
Scenario 1.1: “Self-driving car error causes injury to passenger: first-party A&H policy could respond in first instance.”
Viability rating: Plausible (2.6 out of 5)
Magnitude rating: Medium (3.15 out of 5)
Overall impact rating: Low (8.19)
This scenario, suggested by the LMA Personal Accident Committee, was the top-rated concern arising from A&H underwriters in respect of AI exposures. It is noted that the primary scenario is, at its core, a motor insurance exposure. However, the committee felt that this scenario was sufficiently viable in respect of personal accident losses to include in the personal accident suite of scenarios, notwithstanding the potential for subrogation against at-fault parties (i.e. motor insurers, motor manufacturers, AI system suppliers) in subsequent cost-recovery actions.
Use of AI by insureds and growth potential
Use of AI was assessed as relatively low at present; over 60% of respondents were of the view that AI was being used “in a few cases” and 18% “in some cases”.
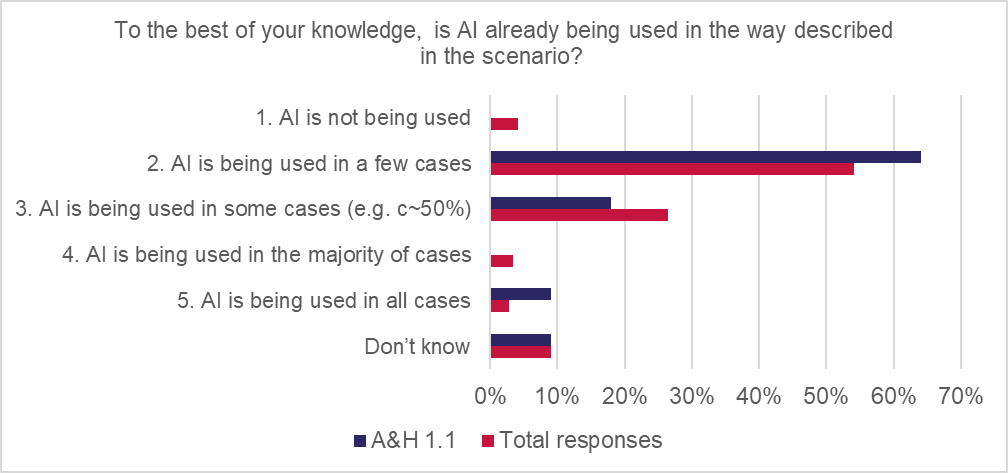
However, 64% of respondents said that AI would be more widely used in 12 months, and 91% said it would be more widely used over the next two-to-three years.
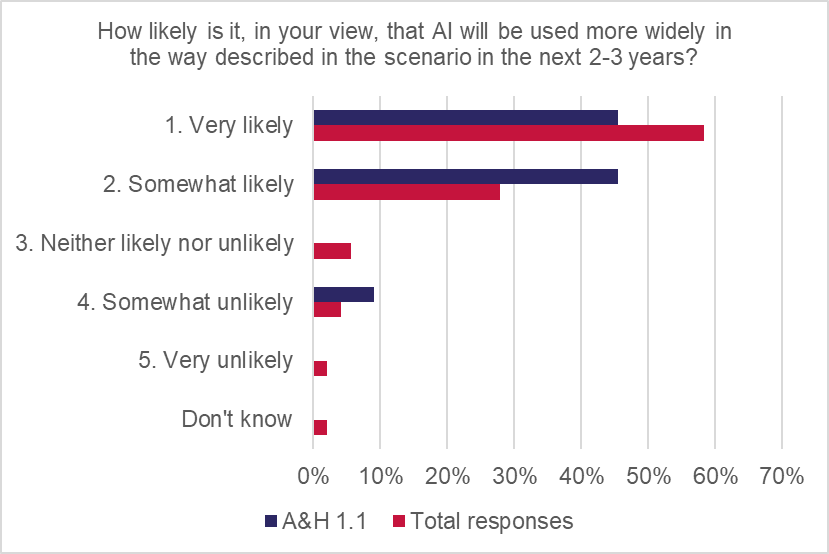
AI was believed to be taking real-world actions in real time in this scenario. 100% of responses agreed that AI would decide which real-world action to take, with the distribution evenly split between “very likely” or “somewhat likely”.
Risk management
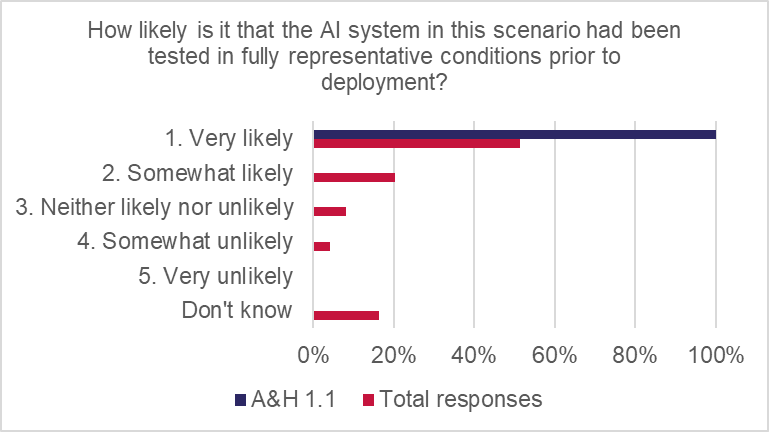
Respondents had strong confidence in testing by product manufacturers: 100% said testing was being done in representative conditions. 64% of responses said that testing by risk managers was adequate to reduce the risk to an acceptable level “in most cases” and 9% said testing was “adequate to reduce risk of causing a severe loss”. However, 27% said testing was “inadequate to reduce or manage risks”.
Losses
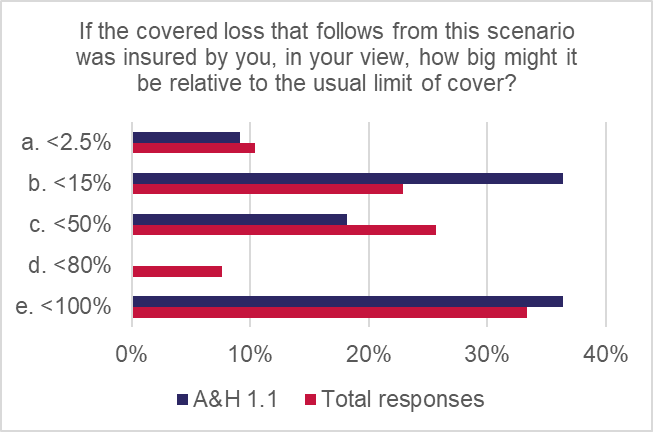
There was no clear consensus on potential scale of loss, with views fairly evenly balanced across the potential range:
- 9.1% said <2.5%
- 36.4% said <15%
- 18.2% said <50%
- 36.4% said <100%
Observations and commentary
This scenario is clearly live already and operating at scale, although respondents still indicated only moderate use of AI, perhaps reflecting minimal losses attributable to self-driving car-related accidents to date. (Note: self-driving car systems fell within the LMA’s definition of AI for the purpose of this survey.)
Respondents were confident that exposure would also increase significantly in the near future, as drivers and passengers would be increasingly exposed to self-driving cars.
There was a lot of confidence in the testing regime applied by vehicle manufacturers and existing risk management practices, but still around a quarter of respondents were concerned that the existing processes were not enough to manage risks.
The viability rating was assessed as “plausible”, with a weighted score of 2.6 out of 5, indicating that the scenario is viable but is not necessarily expected to produce high-frequency losses. This may reflect an underlying tension between high-frequency exposure and strong risk management.
The magnitude rating was assessed as “moderate”, with a weighted score of 3.15 out of 5, indicating that there was clearly some potential for losses. However, respondents were split between views indicating low, medium and high claims values. Given losses in this scenario would be the product of injuries arising from motor vehicle accidents, it is perhaps reasonable to expect a relatively normal distribution of injury severity and correlated cost implications.
The overall impact of this scenario would also depend on the legal system in operation; in some jurisdictions (such as the UK[1]), motor insurers will be held liable for injury caused to drivers and passengers, meaning personal accident insurers that pay first-party claims may be able to subrogate against an at-fault party, which could significantly mitigate losses. Many jurisdictions are still considering the most appropriate method for injured parties to pursue legal recourse.
Cyber scenario
Scenario 10.1: “System downtime caused by AI malfunction and resulting in business interruption.”
Viability rating: Plausible (3.42 out of 5)
Magnitude rating: Minor (2.87 out of 5)
Overall impact rating: Moderate (9.82)
This scenario was intended to capture views from cyber insurance practitioners on insured losses that might flow from an insured’s system downtime, caused by malfunctioning AI. The precise cause of the AI error was not specified but the scenario implies that the AI deployment has a degree of system control or integration, to the extent that an AI error could cause a system failure that is sufficiently severe that business interruption losses occur.
Use of AI by insureds and growth potential
There were different views from respondents on the extent to which AI is currently being used by insureds in the way described in the scenario (i.e. integrated into an insured’s computer system to the extent that an AI error could take the system offline, causing business interruption losses). However, all respondents agreed that AI was currently in use, in this way, at least some of the time:
- 25% of respondents said that AI was already in use “in the majority of cases” and 25% said that AI was in use “in some cases”.
- 50% said “in a few cases”.
No respondents said that AI was not in use in the way described in the Cyber scenario.

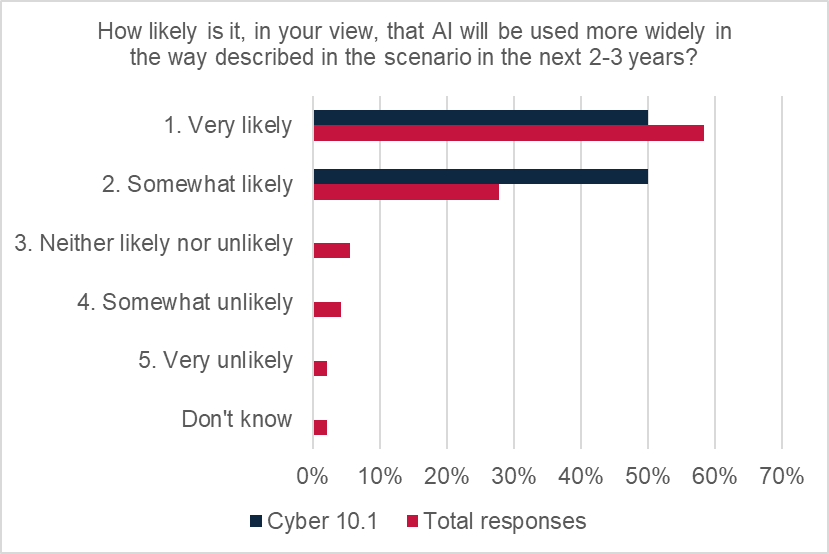
There were mixed views from respondents on the degree of growth of the use of AI (in the way described in the scenario) over the next 12 months. 37% of respondents felt it was “very likely” that AI will be used more widely. However, there was some disagreement, with 25% of responses saying it was “somewhat unlikely”, and 25% saying “neither likely nor likely”.
There was stronger agreement about more widespread use of AI, in the way described in the scenario, over the next two-to-three years, with all responses indicating growth. 50% of respondents indicated AI was “somewhat likely” to grow and 50% indicated it was “very likely” to. These observations are very much in keeping with the total responses to this question across all scenarios, where 86% of all respondents agreed that growth in the use of AI was either “somewhat likely” or “very likely”.
Risk management
There were mixed views from respondents on how well they felt insureds were managing the risks of AI-caused system failure. Over half of responses expressed the view that it was likely that testing was being done in representative conditions prior to deployment, with 37.5% expressing it was very likely and 25% somewhat likely.
However, others thought it was neither likely nor unlikely (12.5%) or didn’t know (25%) whether the AI systems had been sufficiently tested.
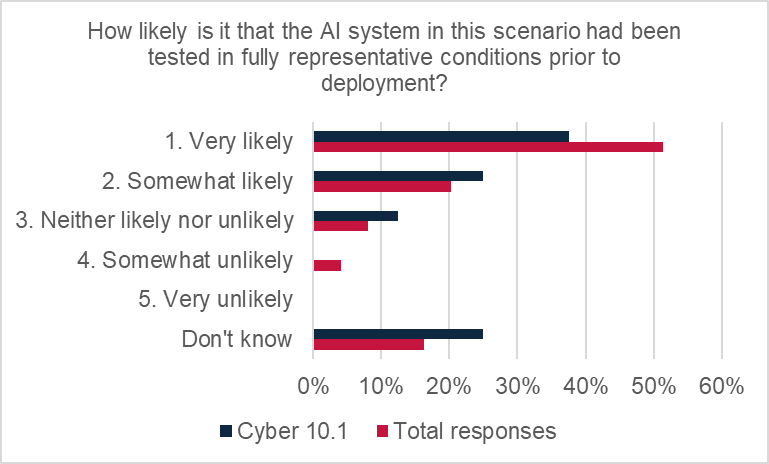
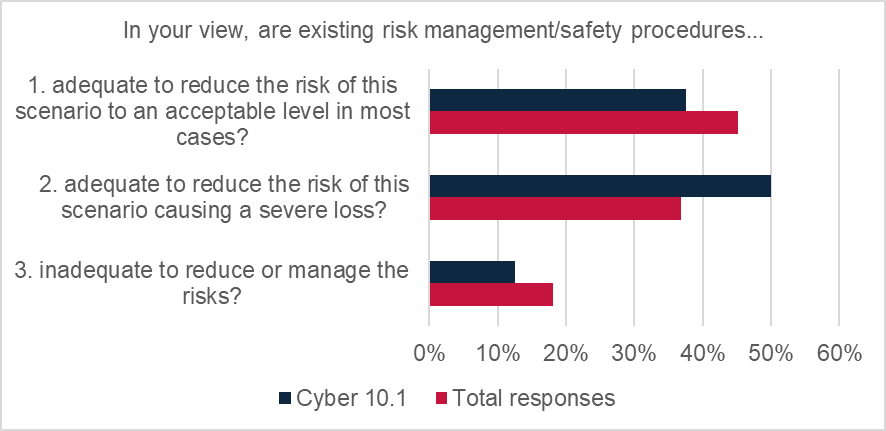
However, there was a strong degree of confidence that existing measures were acceptable in most cases (37.5%) or adequate to reduce risk of scenario causing a major loss (50%). Only 12.5% of responses indicated that existing procedures were inadequate to reduce or manage the risks.
Losses
There was a mix of views on potential loss size arising from this scenario.
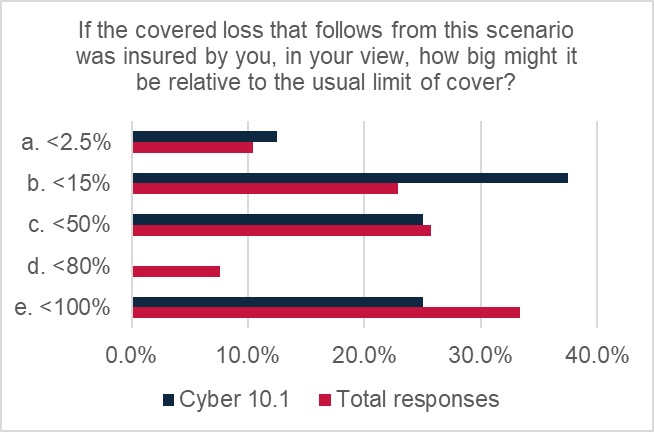
The modal average response was <15% of typical limits (37.5% of responses), indicating that over a third of respondents were not overly concerned about loss size.
However, 25% of responses indicated losses could be up to 50% of typical limits and 25% said losses could be up to 100% of limits.
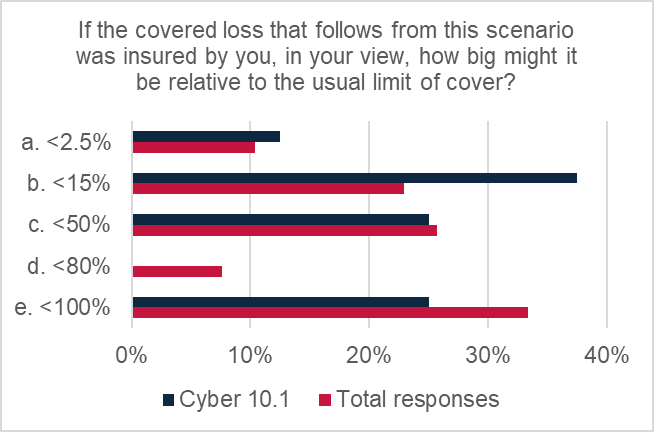
On balance, the weighted average magnitude rating was 2.87 out of 5, labelled as “minor” on the magnitude scale.
Observations and commentary
This scenario probably goes beyond use of large language models. Sophisticated AI search engines and data analysis functions are not typically integrated with operational functions enough to cause a system failure. What is being contemplated here is the use of AI in a way that connects to core operational functions of an insured’s computer system (assuming the connection is deliberate) – scenarios that are perhaps more likely to arise in design or manufacturing settings. The way in which insureds use AI will vary considerably from case to case, depending on a wide range of factors, but it is interesting to note that all respondents agreed that there was at least some degree of risk of system failure posed by AI usage at present.
There was a wide range of views from respondents on key questions in this scenario, perhaps reflecting the breadth of the scenario and/or the wide range of complexity of the underlying risks. The issues arising may be better explored with a case study, where a precise event profile, wording and limits exposed could be reviewed in detail.
The viability rating for this scenario was “plausible” (3.42 out of 5), which sits in the middle of the viability scale, indicating that this type of loss scenario is a credible possibility but not “likely” or “very likely”.
The magnitude rating was “minor” (2.87 out of 5), indicating the view from respondents that this scenario could produce minor losses, with over a third of respondents suggesting a loss might scale at 15% of typical policy limits. However, it is noted that this score is very close to the next threshold (3 out of 5), which would have increased the rating to “medium”. There were also views from half of respondents fearing more substantial losses, indicating losses could be 50% or more of typical policy limits. It is difficult to estimate loss potential, as the values depend on so many different variables, but it is interesting to note the overall view that at least minor losses could arise from this scenario and also a sizeable proportion of respondents felt that losses could be much more significant.
The “plausible” viability rating of this scenario and mixed views on magnitude, averaging out as “minor”, led to an overall impact rating of “moderate” (9.82), although this score was at the lower end of that category. This overall rating perhaps reflects the general views of this scenario; a reasonably high potential of losses arising, moderated by strong confidence in risk management by insureds and an overall minor scale of losses expected per event.
Treatment of AI risk in model wordings
In 2024, the LMA undertook a review of the potential AI coverage position in the LMA’s suite of model cyber clauses. A summary table is provided in Annex 2, updated to include model cyber wordings published up to November 2025.
In this review, AI is recognised as a sub-set of software and therefore falling within the definition of Computer System, widely used in LMA model Cyber clauses:
Computer System means any computer, hardware, software, communications system, electronic device (including, but not limited to, smart phone, laptop, tablet, wearable device), server, cloud or microcontroller including any similar system or any configuration of the aforementioned and including any associated input, output, data storage device, networking equipment or back up facility, owned or operated by the Insured or any other party.
The potential AI coverage position, for each model clause, is indicated with a “low”, “medium” or “high” rating, based on assessment of whether the clause is:
- Low: fully excluding cyber risks.
- Medium: an exclusion of cyber risks with a write-back of cyber coverage or an affirmation of cyber risks coverage with a limitation.
- High: a full grant of cyber coverage with no cyber-specific restrictions but subject to the other terms and conditions of the policy.
Disclaimer: The summary table in Annex 2 is intended to be indicative of potential AI (cyber) risk; the actual risks present in any contract will depend on the wording(s) used and the circumstances. The LMA accepts no liability to any party in respect of the information provided herein.